%20(1).png?width=1080&height=227&name=YOSHIDUMI_01%20(3)%20(1).png)
先日、 Google Workspace Marketplace という Google ユーザー向けのアプリマーケットに弊社で開発したアプリケーションを申請したのですが、アプリケーションの内容に関して Google 側からかなり厳しいチェックを受けました。利用規約やプライバシーポリシー、アプリケーションの概要から内部で利用する Google APIの利用目的等、アプリケーションの内容をフォーマット通りに詳細に申請する必要があり、非常に手間がかかりました(実はまだ解決していません)。数年前、Chromeアプリを申請したときはここまで厳しいチェックを受けなかった記憶があり、非常に驚きました。しかし、これは Google だけが特に厳しいわけではなく、その他のビッグテックも同じように厳しいチェック機構を設けているようです。一体なぜ、ここまで厳しいチェックが入るようになったのでしょうか。背景には「ケンブリッジ・アナリティカ事件」の影響があると思われます。

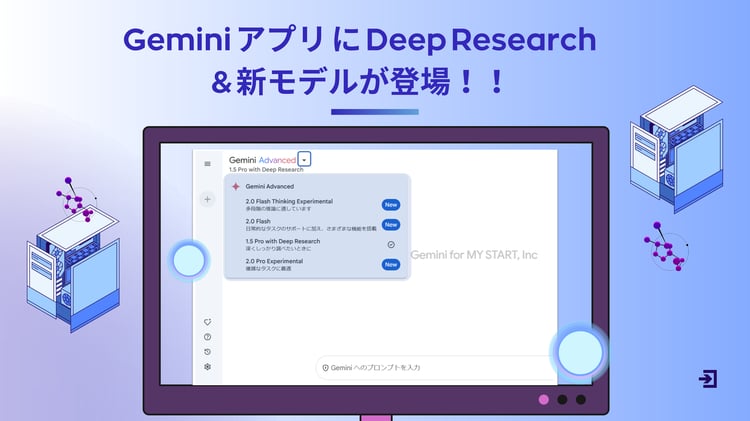
Bard が Gemini へと名称変更
2024年2月8日、これまで「Bard」と呼ばれていた生成AIモデルは、「Gemini」に改名されることが発表されました。
最上位の対話型生成AI「Gemini Advanced」も発表し、日本では月額2900円で提供を開始しました。現在、言語は英語のみですが順次日本語にも対応する予定となっています。
また、GeminiやGemini Advanced が使えるスマートフォンアプリが提供されます。

https://japan.googleblog.com/2024/02/bard-gemini-ultra-10-gemini.html
本記事では、記事公開時点での「Google Bard」の情報について執筆しているため、現在の内容と異なる点がある可能性がございます。
ケンブリッジ・アナリティカ事件とは
私がこの事件を知ったのはNetflix映画「監視資本主義: デジタル社会がもたらす光と影」を観賞したことがキッカケでした。この映画は、人間自身が開発したITテクノロジーによって、「如何に人間の行動は影響を受けているのか」「人間が如何にコントロールしやすい生き物であるか」、警鐘を鳴らしています。そして、この映画の中で紹介されたのが「ケンブリッジ・アナリティカ事件」です。
ケンブリッジ・アナリティカ事件は、2018年に発覚した大規模なデータプライバシー違反事件です。この事件は、個人のデータが許可なく政治的目的に使用されたことで、データ保護とプライバシーの重要性が大いに注目されるキッカケとなりました。ケンブリッジ・アナリティカ(CA)は、イギリスに本社を置くデータ分析会社で、当時、選挙キャンペーンの最適化を目指す顧客に対し心理学的プロファイルを提供していました(現在は倒産)。CAは、50万人のFacebookユーザーから直接許可を得た上でデータを収集しましたが、Facebookのプライバシーポリシーにより、これらのユーザーが友人として接続している他の数百万人のユーザーデータにもアクセス可能になっており、その結果、約8700万人のユーザーデータが許可なく収集され、これが後の大事件の引き金となりました。CAは、2016年の米大統領選挙でドナルド・トランプ候補のキャンペーンに関与したことでも知られています。収集されたデータは、選挙広告の最適化や、特定の選挙区でのメッセージ調整のために使用され、影響力を持つことが可能でした。事件が公になると、Facebook(当時)は国際的な批判の矢面に立たされ、個人情報の扱いに対する慎重さを求める声が高まりました。同社は、情報漏洩を謝罪し、プライバシーポリシーを強化しましたが、その信頼回復には時間がかかりました。また、CAは2018年に破産を申請し、事業を停止しました。ケンブリッジ・アナリティカ事件は、個人データの利用と保護について、国際社会に大きな影響を与え、この事件以降、データ保護とプライバシーは今や社会の重要な議題となっており、企業に対しても、個人情報をどのように取り扱い、保護するかが求められています。ケンブリッジ・アナリティカ事件は、Facebookに限らず、インターネット上の個人情報の取り扱いに対する問題意識を高めたと言えます。
生成AIが第2のケンブリッジ・アナリティカ事件を引き起こす可能性はゼロではない
今後、生成AIが世の中に普及していく場合、多くの個人情報が生成AIの学習データとして処理される可能性があります(※1)。その場合、利用者のログデータから個人の性質を予測することが可能となり、悪意があれば、生成AIによって世論を誘導することは理論上可能です。ユーザーが生成AIに投げかけた問いに対して、思考を特定の方向性に誘導することは、提供元の倫理観の欠如によって引き起こされる可能性は十分あります。
※1 生成AIによっては、利用者のインプットを学習データから除外するオプションもありますが、利用者のリテラシーによっては不用意に個人情報を入力してしまうリスクが発生する可能性があります。
一方でAI提供元には大きな抑止力が働いている
もちろん、生成AIの提供元であるビッグテックは、ケンブリッジ・アナリティカ事件以降、個人情報の取り扱いには慎重になっていますし、そもそも社会全体が個人情報の扱いに対して敏感になっています。さらに、内部告発によって、事業が停止するリスクもあり、AIの提供元には多くの抑止力が働いています。実際、前述したNetflix映画「監視資本主義: デジタル社会がもたらす光と影」では、 Google やApple等のビッグテック出身者が内部事情を証言しています。倫理的に問題がある企業の動きは内部の従業員によって、問題がオープンになる可能性があり、これは一つの抑止力として企業に対して働いていると思われます。
Google Bard は利用者の個人情報をどのように取り扱っているのか
前提として、 Google のサービス全般に対する個人情報の扱いは、 Google が定めるプライバシーポリシーに準拠しています。ページを見ると、トップページに以下のような宣言が記されています。
|
お客様が Googleのサービスをご利用になる際、Google は、お客様の情報を託していただくことになります。Google はこのことに伴う重大な責任を認識し、お客様の情報を保護し、お客様がご自身の情報を管理できるようにすべく尽力しています。 引用元: Google プライバシーポリシー |
このプライバシーポリシーの対象には、もちろん Google Bard も含まれます。「ご自身のデータ」とは、 Google Bard でいうアクティビティ、つまり Bard との会話内容が該当します。Google の個人情報の取り扱いに関する全体方針について知りたい場合は、本ページを確認することが最も正確だと思います。本章では、その上で Google Bard がどのように個人情報を取り扱っているか、説明します。
Google Bard が取り扱うデータの種類
Google が公式で公開している「Google Bard のプライバシー」を確認すると、以下のデータを収集していると明文化しています。
- Google Bard との会話
- 関連プロダクトの使用に関する情報
- デバイスから取得したユーザーの現在位置
- ユーザーからのフィードバック
なぜユーザー情報を収集するのか
Google がユーザー情報を収集したい一番の目的は、 Google プロダクトの品質向上です。特に Google Bard といった生成AIに関しては、学習データが品質向上の鍵を握るため、同意の元、ユーザーの情報を収集・活用したいと考えています。ユーザーの位置情報を獲得したい理由は、地理情報に関するリクエストに対して、ユーザーの現在地を情報元とした精度の高い回答を生成するためだと思われます。

もちろん、収集した情報は、前述したプライバシーポリシーに従って処理されます。
Google が明文化する注意事項
Google Bard の利用に関して、 Google は利用者に以下の注意事項を提示しています。今回のテーマに該当する、注意すべき事項は(1)と(4)になります。(4)については、 Google として処理のプロセスには注意を払っていますが、ユーザー自身にもデータ入力に対して注意を促しています。
- Bard は最適な回答を提供するために、ユーザーの位置情報と過去の会話を使用します。
- Bard は試験運用中の技術であるため、生成される情報は不正確または不適切な場合がありますが、Google の見解を述べるものではありません。
- 医学上、法律上、金融上、またはその他の専門的な助言として、Bard の回答に依拠しないでください。
- Bard との会話に機密情報またはセンシティブな情報を含めないでください。
Bard の会話内容の処理プロセスに人間が関わっている
Google は収集する Bard の会話内容を人間の目でチェックしているようです。世界中で利用されるサービスに対して、人間のレビュワーがチェックすることはあまり現実的ではないように感じますが、何かしら最適化されたプロセスがあり、効率的に処理ができるようになっているのでしょうか。ただし、 Google としても Bard との会話の中に第三者を特定できる情報は含めないように警告をしています。
|
品質の向上とプロダクトの改善のため、人間のレビュアーが Bard との会話を確認し、注釈を付け、処理を行います。このプロセスの一部として、プライバシーを保護するための措置が講じられています。これには、レビュアーが Bard との会話を確認したり注釈を付けたりする前に、その会話と Google アカウントとの関連付けを解除する措置も含まれます。Bard との会話にはご自身や第三者を特定できる情報を含めないようお願いいたします。 |
Google に対して異議を申し立てる方法
Google Bard の出力結果に対して、異議を申し立てる場合は、以下の通り、出力結果の右上部にあるアイコンから「法的な問題を報告」を選択します。


まとめ
Google は個人情報の取り扱いに関しては、慎重に管理・処理していることを明文化していますが、データのインプットに関しては、利用者に対して、「ご自身や第三者を特定できる情報を含めないようお願いいたします」という注意喚起を行っています。つまり、あくまで利用者自身が自己責任で Google Bard を使うことを明言していると言えます。プライベートで使う分には個人の責任の範囲となりますが、企業で利用する場合、そうはいきません。企業で Google Bard を活用する場合、より良いアウトプットを生成するためのプロンプトエンジニアリングも重要ですが、前提としてプライバシーポリシーに関する教育も重要になってきます。 Google Bard を利用する場合、ただアカウントを開放するだけでなく、教育の設計も含めて考えていく必要がありそうです。
.png)

共有ドライブ( Google ドライブ)のセキュリティリスクをどう防ぐか
【新機能】Google Bard のマルチモーダル機能「 Google レンズ 」がすごい

14:00-15:00 オンライン
Google Workspace vs. Microsoft 365 徹底比較! ~ Gemini で加速する生成AI時代の働き方~
詳細はこちら

11:00-12:00 オンライン
AppSheet ハンズオンセミナー~ノーコードでタスク管理アプリを作ってみよう!~
詳細はこちら

11:00-12:00 オンライン
中小企業のためのDX推進!GAS×生成AI活用術セミナー
詳細はこちら

14:00-15:00 オンライン
データはすべてドライブへ!Google ドライブ運用まるわかりセミナー
詳細はこちら

14:00-15:00 オンライン
Gemini と NotebookLM でビジネスを加速! ~ Google Workspace との連携で実現する、生産性向上と DX 推進~
詳細はこちら
オンラインセミナー開催中